

Technical Writing with Pandoc and Panflute
The Tower of Markup Babel
Those of us of a certain age, and with the need to write technical papers, mathematical or otherwise, are likely to be intimate with TeX and LaTeX. We studied Donald Knuth’s TexBook, climbed the ferocious learning curve, and were pleased with the result. Our papers may or may not have been any good, but they certainly looked good.
Then, the Web took over the world, seemingly overnight. Some of us wanted our work to live in this new, online environment, so we learned a wholly new system of markup. Then, a third language: CSS (Cascading Style Sheets), and maybe even a little JavaScript.
We still wrote our real work in LaTeX, while turning to HTML for our hobbies. If we wanted to put one of our papers on the web, we resorted to one of several options for translation from LaTeX to HTML. None of these were excellent, but they could produce some approximation of how the paper was supposed to appear. Of course, we could always translate our papers by hand, but most people were, naturally, galled by the duplication of effort this entailed.
Since TeX is a Turing-complete language, it is generally impossible to translate it into a declarative markup system such as HTML. Several projects address this problem by defining a subset of LaTeX allowed for input. A better approach is that followed by Docbook, Tbook, Pandoc, and some others: define a more general markup language, or system of XML tags, and translate that into any of the desired targets. Pandoc, one of the subjects of this article, offers more than that, promising to translate between many possible pairs of formats. However, its parsing of some of these, including, critically, LaTeX, is faulty or incomplete. This needn’t concern us, because the best way to unlock Pandoc’s power is by using its “native” input format, which is an extended dialect of Markdown. Pandoc can translate this into a really impressive set of output formats, including not just LaTeX and HTML, but even ODT and docx, so we can communicate with colleagues unfortunate enough to be stuck using Word. Pandoc is a mature free software project; a recent version is probably available through your system’s package manager. And if you use LaTeX, you probably know that the best way to outfit yourself is by installing the Tex Live distribution, either through your package manager or directly from the Tex Users’ Group source.
If you are familiar with Markdown you may be skeptical of the abilities of a system based upon it, as the original Markdown is too anemic for any type of complex or technical writing. However, Pandoc’s extended version of Markdown, while retaining its simplicity for simple things, allows you to include LaTeX math, bibliographic references, internal and external hyperlinks, tables, language-specific syntax highlighting, bulleted and automatically numbered lists, images with captions, and much more.
Here is a simple example of Pandoc's Markdown.
That was the first paragraph. This is the second.
It was originally based on email conventions.
You can have *italics*, **boldface**, and
~~strikethrough~~ text.
Creating hyperlinks is as easy as
[example.com](http://example.com);
you can also use your
[BibTeX keys][@winterberg2004] this way.
Insert LaTeX equations directly, like $e^{iπ} = -1$
In addition to all this, Pandoc has the ability to be extended and customized through filters and templates — and that brings us to the real subject of this article.
Filters
Pandoc works by translating its input into an internal representation, performing certain transformations on the representation, and then translating the result into the desired output format. Because of this architecture, where parsing, transformation, and output are decoupled, developers can add, for instance, the ability to translate a new format by just writing a module for parsing that format into the internal structure; and they can support a new output language just by writing a translation from the internal representation into that language.
Crucial to the advanced use of Pandoc is the idea of a filter. A filter is a program, invoked with a flag on the command line, that steps in after Pandoc has parsed its input, and makes changes to the document’s internal representation. The filter can be indifferent to the eventual output format, or it can do different things depending on the target. For example, when creating HTML you may want to alter the behavior of footnotes so that the conventional superscript with note at the bottom is changed to revealing the footnote text when the reader hovers over the footnoted word.
Some of the useful things that Pandoc does out of the box are implemented as filters. Academic users depend on adding the flag “–filter pandoc-citeproc”, along with the “–bibliography” flag to indicate the location of a BibTex database file. (The system can handle EndNote, MEDLINE, and several other database formats, as well.) This filter takes keys from the BibTex file and turns them into citations in your chosen style, and adds a bibliography to the end. It replicates the abilities of LaTeX/BibTex to handle reference data stored in a BibTex database, but can handle HTML and other output formats besides TeX.
Pandoc is written in Haskell, which makes that the native and most natural language in which to write Pandoc filters. But knowledge of this language is not very widespread. Since Haskell and I are at most distant acquaintances, I turned to panflute, a package for writing Pandoc filters in Python. There are others, but panflute is somewhat easier to use, making the potentially arcane knowledge of Pandoc filters accessible to the average developer. You can install panflute with pip, the Python package manager.
The hardest part of getting up to speed with panflute is learning about its data structures, which shadow the data types internal to Pandoc. But once you become familiar with it, you can do powerful things with very few lines of code. Before we get to the case study that became the impetus for writing this article, let’s have a look at a few simple examples, to get the general flavor of Pandoc filters in Python.
Suppose we’ve sprinkled our article with italics and boldface, but the journal’s editor has just informed us that their house style does not allow bold text. We could resort to a regular expression substitution, but this is notoriously error-prone, especially when applied to textual markup. Here’s a Pandoc filter, using panflute, that changes all instances of bold text to italic, while leaving italic text as-is:
# !/usr/bin/python3
import panflute as pf
def action(elem, doc):
if isinstance(elem, pf.Strong):
return pf.Emph(*elem.content)
if __name__ == '__main__':
pf.toJSONFilter(action)If you save this program as, say “myfilter.py”, then you can say cat file | pandoc --filter myfilter.py to get “file” translated into HTML, with all the boldface turned into italics. You can try it on the Markdown sample above, and experiment with different output formats (using the “-t” flag) to verify that Pandoc will use the correct markup for italics in each case.
This example embodies the basic pattern used in all Pandoc filters. The final two lines cause the program to behave as a filter, walking through each element in the input document and applying the “action”. The action function must have the two arguments shown; the first is the current element, and the second is the entire document. Both refer to Pandoc’s internal version of the document, after the input markup is parsed and translated. For each element, we test whether it’s boldface, which Pandoc/panflute represents as a “Strong” element, and, if it is, return its content (which can contain arbitrary arrays of other elements) wrapped in the “Emph” element, which is used for italics.
Although Pandoc’s extended version of Markdown covers most of the basic elements that an author of technical material is likely to need, you will inevitably wish that it had syntax for something that is not included. There are a potentially endless number of different semantic elements that an author might invent for a document, and no markup language can anticipate them all. In writing for the web, we typically extend the semantics of HTML by defining classes in CSS, for good or ill. In LaTeX, this job usually leads to the creation of macros, which are simple for simple cases but can quickly turn to dark magic. In either case, we resort to inventing a presentational expression of our semantic intent, and working out a special case for each end target that we wish to write for.
Once we know how to write simple Pandoc filters, however, we can leverage some special features of Pandoc’s extended Markdown to extend it further by creating our own customized elements. The first of these special features that we’ll discuss is the ability to add arbitrary attributes to inline code and code blocks.
In running text you can indicate code, commands, or similar text by surrounding it with backticks. You will usually see this rendered in a monospace font, and the author almost always wants it rendered literally (no use of ligatures, for example). The Pandoc/Markdown default is to choose the correct semantic markup for the target language, if one exists. For example, the Markdown input ‘type `ls` to see a listing’ is translated into the HTML ‘<p>type <code>ls</code> to see a listing</p>’ (Pandoc puts fragments into paragraphs).
If you want to include a full-fledged code sample, you have the choice of several syntaxes. For our purposes, the backtick syntax will be most convenient: just put your code in a separate paragraph beginning and ending with a line of three backticks.
Pandoc extends Markdown by allowing you to add arbitrary lists of attributes to these elements. For our purposes, one attribute will serve. For inline code, the syntax is ‘`code fragment`{.attribute}’. For code blocks, it’s even simpler:

You are allowed to place any number of spaces between the opening backticks and the attribute name.
Pandoc intends these attributes to indicate the language name, and uses them to create syntax highlighting for HTML and LaTeX output. You might have noticed that the input example is also syntax-highlighted. This delightful feature is provided by the Vim editor; some details about how to use it are at https://github.com/tpope/vim-markdown.
We don’t have to use these attributes for language names, however. Since we can get at them through panflute filters, we can use them to extend the language by defining our own elements. I’ll give a few examples of elements I defined for my own work.
Soon after I began using Pandoc, I decided I needed a way to include comments in the text that would be passed over, and not copied to the output: a way to “comment out” passages. I was sure that something like this was already part of the language, but some Googling revealed that there was no convenient way to accomplish it. Here is how I decided to implement this using filters: first, I decided on the name for my new attribute: “n”, for “note”. I want to be able to type ‘`ignore me`{.n}’ in running text, or, for longer commented-out passages,
This is text that will be translated, but
``` n
this paragraph,
no matter what it contains,
will just disappear.
```
And we are back to regular input.
and not see those passages in the output.
The filter that does this is pretty simple:
import panflute as pf
def action(elem, doc):
if (isinstance(elem, pf.Code) or
isinstance(elem, pf.CodeBlock)):
if ('n' in elem.classes):
return []
if __name__ == '__main__':
pf.toJSONFilter(action)As before, the first line of the action function looks for inline code or CodeBlock elements. When it finds one, it checks whether our special “n” class is in its list of attributes, called “classes” in panflute. The final line of the action function in a filter will be the transformation of the element. In this case we return an empty list, which accomplishes what we want, by simply deleting the element from the document.
One important detail: you should save your panflute filters in files that end with “.py”, so that Pandoc knows that they are Python programs; otherwise, it will assume they are Haskell and print a mysterious error. You don’t need a separate file for each filter; you can create multiple filters by including all their relevant conditions in one big action function.
Here’s one more simple example that shows what that looks like. It also illustrates output-specific processing: applying different transformations depending on the target. Sometimes I want to put a “publication note” at the beginning of an article on my website, to notify the reader that the article may have been updated, for example. But I don’t want these notes to appear in a PDF (via LaTeX) version of the article. So, I want different things to happen depending on the output format. I call this custom element “pubnote”; here is the previous filter with the pubnote rule added:
import panflute as pf
def action(elem, doc):
if (isinstance(elem, pf.Code) or
isinstance(elem, pf.CodeBlock)):
if ('n' in elem.classes):
return []
if isinstance(elem, pf.CodeBlock):
if 'pubnote' in elem.classes:
if doc.format == 'html':
return pf.convert_text(
'<div class = "pubnote">{}</div>'
.format(elem.text))
else:
return []
if __name__ == '__main__':
pf.toJSONFilter(action)This shows the main reason to pass the “doc” argument into the action function: it carries with it attributes global to the document as a whole, including, in this case, the output format requested of Pandoc. If this format is HTML, I would like the publication note simply wrapped in a div with a certain class, so that I can style it appropriately with my stylesheet; if it’s any other format, we can expunge it. I used the function convert_text to get this done; this function takes its argument, as if it were a Pandoc input string, and passes it through Pandoc, using the active output format. The example also shows one way to extract the contents of an element, with its text attribute. You can get more information about the Element class and the rest of the panflute API at http://scorreia.com/software/panflute/code.html.
Templates
Your document can define global variables that are carried through the translation process until the end. We’ve already seen one: the output format, culled from the command line flag, that you can access in your filters as doc.format.
The panflute API extends code blocks to contain YAML data. YAML is a data description language, like XML, but less verbose and easier on the eyes. You can use this to define named variables, right in your document, of various types, including lists of values.
Here’s a simple example of how I use this facility in my personal set of filters. Sometimes I want to include a short quotation, or epigraph, at the beginning of an article or chapter. The epigraph has two distinct components: the quote itself, and the person it is attributed to.
~~~ epigraph
quote: Simplicity is the ultimate sophistication.
who: Leonardo da Vinci
---
~~~ I can include this data block anywhere in the document. My convention happens to be to use a row of three tildes, as you can see, but backticks work as well. Panflute will put the variables, defined between the start of the block and the “---” line, into a Python dictionary: {'quote': 'Simplicity is the ultimate sophistication.', 'who': 'Leonardo da Vinci'} The space between the “---” line and the line ending the data block is for optional data.
Here is filter that processes the “epigraph” blocks. It assumes HTML output, but from the examples above you will understand how to extend it to handle other formats. I’ve used the convenience function yaml_filter, which is part of panflute, and handles the parsing of YAML-extended code blocks. You pass it as an argument to the toJSONFilter function that we’ve seen before, along with a dictionary of tags. This dictionary associates attribute names with which you tag your data blocks with function names. The first argument to these filter functions will be the dictionary of values parsed from the block, while the second will be the optional data. The element and doc arguments are as we’ve seen previously.
import panflute as pf
def epigraph(options, data, element, doc):
return pf.convert_text(
'<div class = "epigraph">{}
<span class = "who">{}</span></div>'
.format(options.get('quote'), options.get('who')))
if __name__ == '__main__':
pf.toJSONFilter(pf.yaml_filter,
tags = {'epigraph': epigraph})You can also use the global variables from your YAML blocks in Pandoc echo "*Hello*, **world**" | pandoc to get the phrase translated into the default HTML, or into LaTeX by adding the flag -t latex. When creating entire documents, however, you invariably need other material surrounding the text. For web pages, you’ll have a header linking to your site’s stylesheet and probably much more, and body and html tags. When using LaTeX, you will need a preamble that defines your document class, loads all the required packages, and, quite likely, defines all your personal macros and definitions.
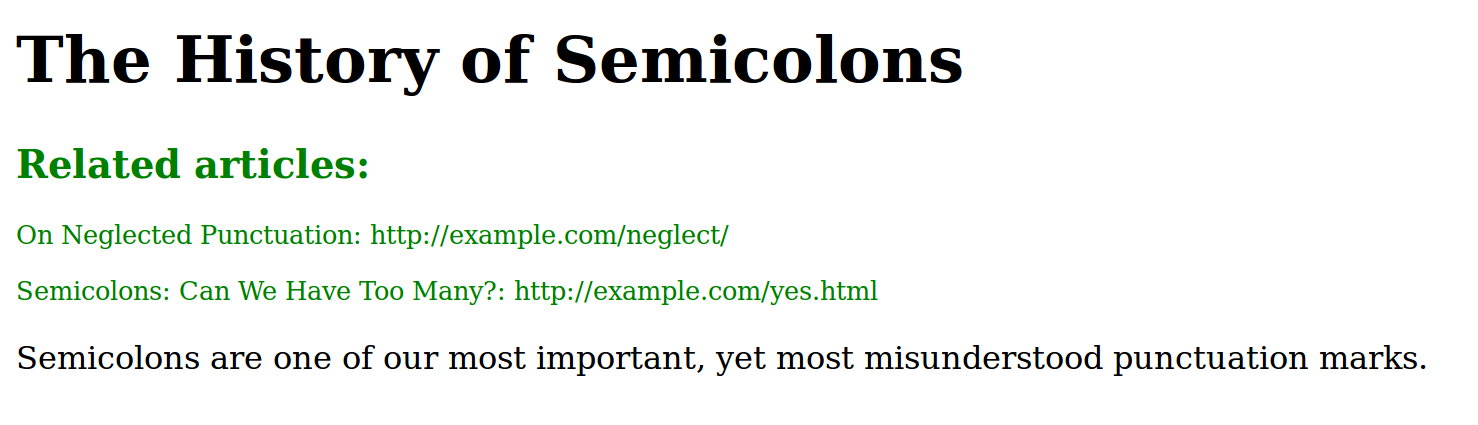
If you supply the –standalone flag to Pandoc, it will embed the translated content into a default template appropriate for your chosen output format. These templates are quite capable, including such things as style definitions for the language-specific syntax highlighting that we mentioned above. However, they are rarely what you want. You will inevitably wind up creating your own templates for real work. Fortunately, this is quite simple. You need merely to take whatever template you are already using for document creation, and add placeholders for global variables defined by Pandoc and by you in your document. These are variable names surrounded by dollar signs. The main one, $body$, contains the translated text of your document. Other sources for global variables are the YAML-extended code blocks that we’ve introduced above, certain command-line flags, the general flag --variable, unnamed YAML blocks, and Pandoc title blocks. For these last two, see the Pandoc documentation for all the details. Remember to save your templates with filename extensions that match their format: .html for HTML and .latex for LaTeX. Here’s an example of an unrealistically simple HTML template, showing the use of two variables. It also serves as an example of three very useful features of Pandoc’s template language: conditions, looping over variable lists, and extracting fields from variables.
<!DOCTYPE HTML>
<html dir="ltr" lang="en-US">
<head><meta content="text/html;charset=utf-8"
http-equiv="Content-Type" />
<title>$title$</title>
</head>
<body>
<h1>$title$</h1>
$if(related)$
<div style = 'font-size: 0.8rem; color: green;'>
<h2>Related articles:</h2>
$for(related)$
<p>$related.title$: $related.url$</p>
$endfor$
</div>
$endif$
$body$
</body>
</html>Here is the small Pandoc/Markdown document that we’ll use as input to this template. It begins with an standard YAML block, that Pandoc uses to automatically populate the metadata variables used in the template. This is the syntax that panflute extends to define the YAML-extended data blocks that we used earlier. Notice the terse yet readable syntax for lists and variable attributes defined by YAML syntax.
---
title: The History of Semicolons
author: Prof. Lexi Graphical
related:
- title: On Neglected Punctuation
url: "http://example.com/neglect/"
- title: "Semicolons: Can We Have Too Many?"
url: "http://example.com/yes.html"
---
Semicolons are one of our most important,
yet most misunderstood punctuation marks. This figure shows what the resulting HTML document looks like when rendered in a browser:
Automating a Complex Document
Since Pandoc filters, using the panflute package, are just Python programs, they can do more than merely modify the document translation: they can perform any processing that we desire. In particular, as Python is a good “glue language”, in which it’s easy to invoke external processes and perform system functions, we can allow the document to trigger this processing, and include the results in the finished product.
This final section is a case study showing how to use Pandoc filters and templates to automate away the tedious and error-prone tasks that happen to be involved in creating a certain complex document. I hope that this detailed example will make the principles clear, so that you take away the ability to apply these techniques in creating your own documents, even though they are unlikely to be similar to my particular case.
The example is an ebook about gnuplot, the open-source plotting program. The book consists almost entirely of example gnuplot scripts and their output, side by side, with a paragraph or so of explanation for each example. On other words, it is similar to a recipe book. I enforce a firm rule: each script must work as presented, and the figure displayed with it must be the exact output of the script. This is more troublesome than it might sound at first. One winds up with hundreds of scripts, and hundreds of image files. If I decide to alter one of the example scripts, I must ensure that the image printed next to it is the output of the new script, and not a stale one. I use boldface highlighting, and other presentational details, in the printing of the example scripts, to help the reader, but this involves markup that can’t be fed to gnuplot.
The system that I will describe here allows me to simply type the gnuplot scripts along with the text, adding special characters for boldface highlighting. A collection of filters and the output template take care of all the rest. They: (1) replace my highlighting character with the LaTeX command for boldface; (2) take care of line continuations; (3) compute a checksum of the executable version of the script (with formatting characters removed); (4) define a hypertarget in the document using this checksum; (5) include the executable version of the script in the output as a PDF attachment; (6) process the script with gnuplot and save the resulting graph as a PNG, using the checksum in the name, if the image file does not already exist; (7) include the PNG in the output; and (8) create an index of plots, linking to their locations in the book using the hypertargets in step 4.
Using this system, I can make alterations to the examples at will, without having to worry about breaking anything or keeping track of what goes where. Any change in the script will lead to a changed checksum, so the program knows to run gnuplot on the changes and make a new figure. After using it to help process almost 200 pages of text, it’s pretty well tested, and I feel that the time spent setting it up was well worth the resulting savings in headaches and tedium, allowing me to concentrate on the more enjoyable aspects of writing the book. In addition to the above, there are extra steps for those gnuplot examples that create animations. In that case, another filter creates a set of animation frames, and the system uses ImageMagick to stitch them together into a movie. It creates a poster frame for the movie, attaches the movie to the PDF, copies the movie file to the publisher’s server, and creates a link to the movie file in the book.
Using the techniques for writing filters and templates described above, you already know how to construct a system like this. The only new idea here is using the Python filter to call out to external programs.
Here is the markup for one of the examples in the book. I wrap the gnuplot script in a code block with a “gnc” attribute:
```gnc
@set xrange [-pi : pi]@
plot sin(x)
```
The “@” characters are used to delimit what I want printed in boldface. The following listing shows the filter function that processes these code blocks:
# !/usr/bin/python3
import panflute as pf
import subprocess
c = subprocess.run
import re
import zlib
import os
def action(elem, doc):
if isinstance(elem, pf.CodeBlock):
if 'gnc' in elem.classes:
# pff will hold the checksum
pff = str(zlib.adler32(bytes
(elem.text.replace('@', ''), 'utf-8')))
#The name used for the
#gnuplot output image:
pfn = pff + '.png'
#Check if we've done this one:
if pfn not in os.listdir():
dscript = elem.text.replace('@', '')
script = '''set term pngcairo\n
set out "{}"\n{}'''.format(pfn, dscript)
with open(pff + '.gn', 'w') as scriptfile:
scriptfile.write(dscript)
#Execute gnuplot on the script:
c('''echo '{}' |
gnuplot'''.format(script), shell = True)
if doc.format == 'latex':
#Lot's of escaping needed:
mt = elem.text.replace('{', '\\{')
mt = mt.replace('}', '\\}')
#LaTeX boldface:
mt = re.sub('@(.*?)@', r'\\textbf{\1}', mt)
mt = mt.replace('\\\n', '\\textbackslash\n')
#for newlines in gnuplot labels, etc.
mt = mt.replace('\\\\n', '\\textbackslash{n}')
return pf.RawBlock(
'\n\hypertarget{'+pff+'}{}\\begin{Verbatim}\n'+mt+
'\n\end{Verbatim}\n\\textattachfile[mimetype=text/'
+'plain]{' + pff + '.gn}{' + '\\framebox'+'
{Open script}}\n\plt{' + pfn + '}',
format = 'latex')
else:
return [elem, pf.RawBlock(
'<br /><img alt = "" src = "' + pfn + '" />',
format = 'html')]
if __name__ == '__main__':
pf.toJSONFilter(action)
I’ve pointed out the key steps in code comments. The filter inserts code in the output, such as \plt, that refers to macros defined in the final template. These are simple affairs that handle some formatting, such as inserting page breaks and including the figures at the correct width. The code imports the zlib package for the checksums, and uses the subprocess module to run external programs. It performs filesystem operations using the included os module. The filter inserts commands to use the LaTeX attachfile package to make PDF attachments, which I include in my output template. The RawBlocks are a panflute data structure for “raw text”, and must include the intended output format as a second argument.
Here is a page from the book, where this early recipe appears:

And, finally, here is a fragment of the LaTeX source corresponding to the book fragment, where you can see how the code checksum is used:
\hypertarget{setting-ranges}{\subsection{Setting
Ranges}\label{setting-ranges}}
That was simple. Notice how gnuplot decided to plot
our function from -10 to +10. That's the default,
which we got because we didn't ask for any
particular range. Gnuplot also set the y-axis
limits (the range of the vertical axis) to
encompass the range of the function over that
default x-axis domain. Let's take control of the
limits on the horizontal axis (the new command is
highlighted). Gnuplot happens to know what π is
(but doesn't know any other transcendental
numbers).
\hypertarget{3260812063}{}\begin{Verbatim}
\textbf{set xrange [-pi : pi]}
plot sin(x)
\end{Verbatim}
\plt{3260812063.png}You can use similar techniques to write filters and templates for anything imaginable: perhaps processing images, creating logs, using the results of calculations within documents, checking links, or incorporating information scraped from websites. You can trigger all of these actions through markup that you define to extend Pandoc’s Markdown language, using the panflute API.
I’ve found Pandoc, used with Python-programmed filter functions, to be a powerful system for authoring complex documents. I routinely translate single input files to HTML, PDF (through LaTeX), and .docx for Word-using publishers, with no additional work. For those of us who write for a variety of publications, or simply want to be able to repurpose our manuscripts on occasion, a workflow based on Pandoc is the Holy Grail of authoring systems.
